You’re asking the right question — because most teams completely underestimate how messy EKS becomes when you scale to 50 DevOps + 100 developers. If you don’t design access, tenancy, and cluster structure early, it turns into a permissions and blast-radius disaster.
I’ll give you a realistic large-org EKS architecture + access pattern, not a blog-level diagram.
🧱 Large-Scale EKS Environment — Tree Architecture

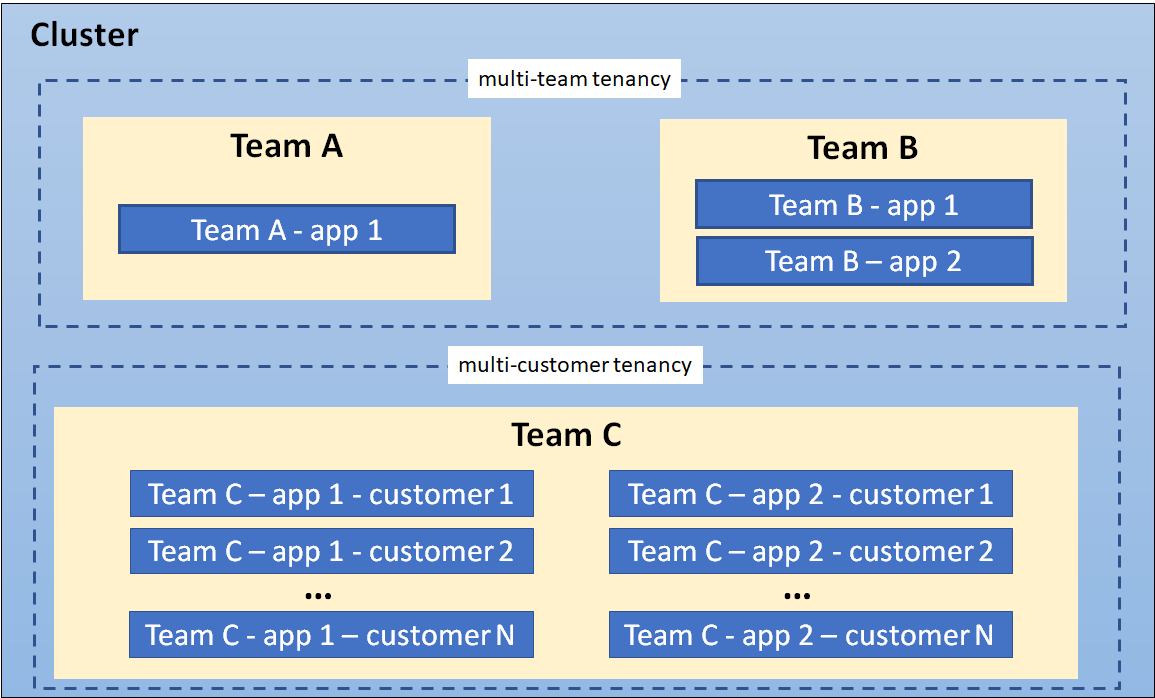

✅ Cluster Layer (Not One Cluster)
At this team size — one cluster is a mistake.
Typical split:
AWS Organization
├── Shared Services Account
│ └── EKS: platform-tools
│ ├── argocd
│ ├── monitoring
│ ├── logging
│ └── security agents
│
├── Dev Account
│ └── EKS: dev-cluster
│
├── Staging Account
│ └── EKS: staging-cluster
│
└── Prod Account
└── EKS: prod-clusterReason:
- blast radius control
- IAM boundary
- billing isolation
- compliance separation
If you keep dev/staging/prod in one cluster at this scale — you’re inviting outages.
👥 Access Model — Who Gets What
In serious environments, developers never get direct cluster-admin. Ever.
DevOps / Platform Team (Small Group)
Cluster Admin
Node group control
IAM + IRSA management
Network policies
Storage classes
AddonsAccess via:
- AWS IAM → mapped in aws-auth configmap
- RBAC cluster-admin
- break-glass role with MFA
Developers (Large Group — 100+)
They get:
Namespace-scoped access only
kubectl limited verbs
No node access
No cluster-wide objectsRBAC example:
Role:
namespace: payments-dev
verbs: get,list,watch,create,update,patch
resources: pods,deployments,servicesThey cannot:
- create CRDs
- change storage classes
- touch ingress controllers
- modify network policies
If they can — your platform team failed.
🧭 Namespace Strategy (Critical at Scale)
Per team OR per service group:
team-a-dev
team-a-stage
team-a-prod
team-b-dev
team-b-stage
team-b-prodEach namespace gets:
resource quotas
limit ranges
network policies
service accountsWithout quotas → one bad deployment eats cluster CPU.
🔐 Authentication Flow in Large EKS
Real flow:
User → AWS SSO / IAM Identity Center
→ IAM Role
→ aws-auth configmap mapping
→ Kubernetes RBAC RoleBinding
→ Namespace permissionsNobody should use static IAM users anymore.
🚀 Deployment Access Pattern
At scale — humans should not kubectl apply in prod.
Pattern:
Developer → Git push
→ CI pipeline
→ Image build
→ GitOps repo update
→ ArgoCD / Flux
→ Cluster deployDirect cluster writes = reduced to platform team only.
🧩 Multi-Tenant Control Layers
Must-have controls at this size:
OPA Gatekeeper / Kyverno → policy guardrails
Pod Security Standards → restricted baseline
Network Policies → namespace isolation
IRSA → pod-level IAM
Resource Quotas → per namespace
LimitRanges → per containerIf you skip these — one rogue Helm chart can expose your cluster.
📦 Node Group Strategy
Separate node groups:
system-nodes → core addons
platform-nodes → controllers
app-nodes → workloads
gpu-nodes → ML jobs
spot-nodes → batchWith taints:
dedicated=platform:NoSchedule📊 Observability Model
Centralized — not per team.
Prometheus + Thanos or AMP
Grafana (SSO login)
Loki / OpenSearch logs
Cluster-wide metrics
Namespace dashboardsDevelopers get read-only dashboards.
🔥 Hard Truth (No Sugarcoating)
If you try to manage:
- 150 engineers
- single EKS cluster
- shared admin access
- no GitOps
- no namespace isolation
You will:
- break prod repeatedly
- lose auditability
- fight permission chaos
- burn DevOps time on access tickets
Large EKS is a platform engineering problem, not just a Kubernetes problem.
If you want, next I can give you:
- exact RBAC YAML templates for large orgs
- GitOps folder tree at scale
- multi-cluster networking patterns
- cost control strategy at 100+ teams
- real incident failure patterns I’ve seen in big EKS setups
Tell me which layer you want to go deeper into.